Solution Overview
Central Development and Control - Local Processing and Analytics
With the Crosser Stream Analytics & Integration platform you can collect and analyze data close to where the data resides, whether it’s on-premise behind firewalls, in the cloud or at the edge on assets in the field. With it’s clear separation of the management and execution environment you have full flexibility in deciding where each of your use cases will process data, while still managing everything from a central SaaS application.
Quickly build applications by combining pre-built modules into processing pipelines (Flows) in our visual design tool (Flow Studio). Test and verify your Flows from the cloud and then decide which execution environments (Nodes) you want to use for each use case. Once a Flow has been deployed into a Node, all processing happens locally, no data is sent to Crosser.
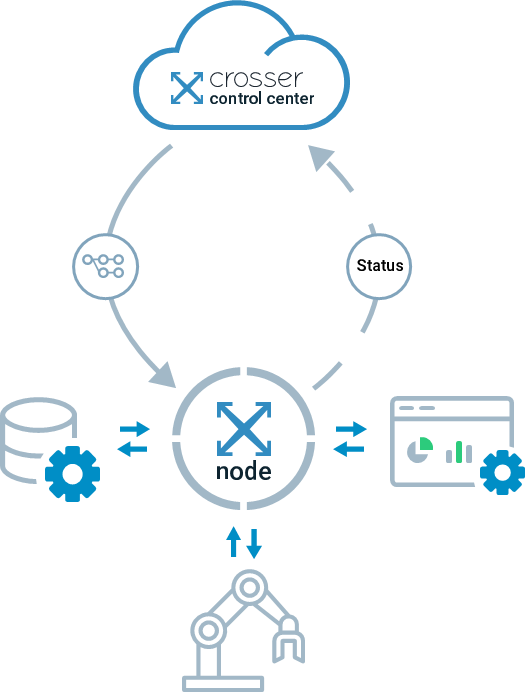
The Crosser Solution has two main parts:
Crosser Control Center
A SaaS service that is used to design the processing Flows to run in Nodes, by using the Flow Studio visual designer. Test your Flows from within the Flow Studio, by running them on Nodes that have access to the systems used by your Flow. Deploy your verified Flows into one or several Nodes and then monitor your distributed execution using the Flow Watch monitoring tools.
Crosser Node - the Runtime
A generic runtime for Flows. Installed as a single Docker container, or as a Windows service, close to the sources of data. This is where data is collected, processed and results are delivered to different receivers, on-premise or in the cloud. Each Node can run multiple Flows and Flows can be updated/added without re-starting the container/service and without affecting other Flows.
Flow Studio - Design, Test, Deploy
The Flow Studio is the low-code development tool used for building Flows.
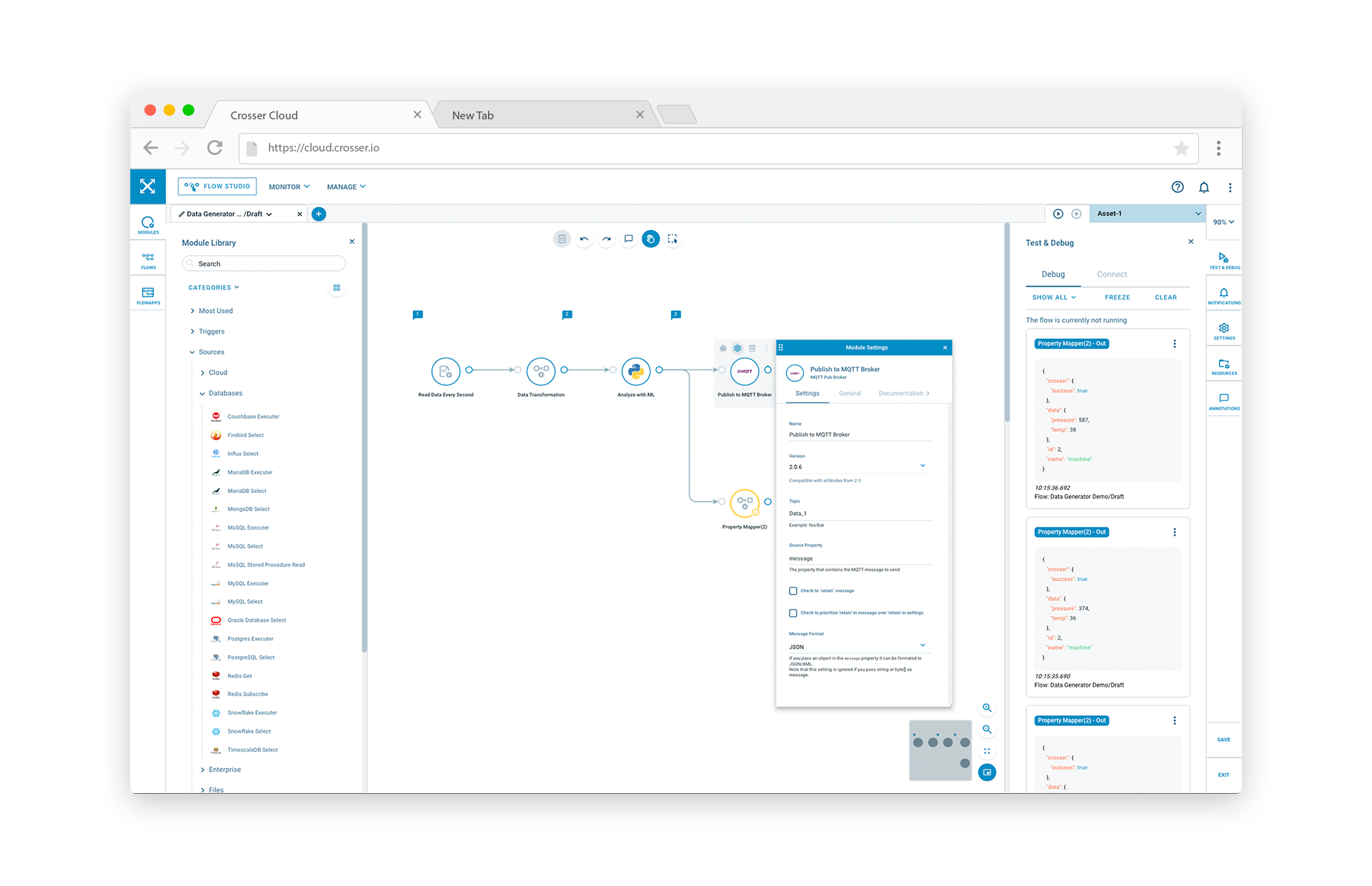
Design
The starting point is the design phase, where you create a Flow to solve a specific problem. You can then start with an empty Flow and add the modules needed, or start with a FlowApp (template) which is close to what you want and then modify it as needed. A module browser is available to help you find the modules you need based on the type of module. You can also search for modules. Drag the modules you want to use into the drawing canvas and then connect them to specify the sequence of operations you want to apply.
Each module needs to be configured for this specific use case. This is done by clicking on the cog-wheel above each module. There is built-in documentation to help you configure the modules.
Test
Being able to test your Flow with real data is key to help you realize your use cases. You can test your Flows at any stage in the design, by connecting to one of your locally deployed Nodes, or by using a Sandbox* hosted by Crosser. Typically you test your Flow step by step, i.e. add an input module, run the Flow to see what data you get from this source. Add some more modules to process this data, test that you get the expected result. Eventually you will have a result and can add output modules to deliver the results to its final destination. Test the whole Flow and verify that you get the expected outputs and that its successfully delivered to your destinations.
*) Sandboxes are only available in the Flow Studio and you cannot deploy Flows permanently. From Sandboxes you will not be able to access local services.
Deploy
The final step, once you have verified your end-to-end Flow, is to decide where this Flow should execute. The Deployment Tool let's you select one or several Nodes to install the Flow into. After a Flow has been successfully deployed, processing will run locally in each of the Nodes until the Flow is stopped or removed.
You don't need to use the Flow Studio again until you want to make changes to a Flow, or create a new Flow. Flows are version controlled and to make changes to an existing deployed Flow you have to create a new version.
Modules
All functionality that you can use when building Flows comes through Modules. You combine modules into Flows to solve a specific use case. Hence, the module library is key. In the module library you will find a large variety of modules that address functionalities needed when solving common use cases. At a high level the following categories are available:
| Sources | Get data from external systems, e.g. files, APIs, PLCs, databases, sensors and SaaS services. |
| Destinations | Send the result of your processing Flows to different destinations (similar list as for Sources). |
| Transformation | Transform your data, e.g. rename, re-structure, filter, aggregate. |
| Process & Analyze | Analyze your data and take actions or deliver processed data to your destinations. Apply conditions, mathematical calculations or advanced algorithms (including ML). |
Custom code & ML
You are not limited to the functionalities offered by the fixed-function modules in the library. You can write code to implement additional functionality. In the library you find modules where you can enter C#, Python, IronPython or Javascript code. With the Python module you have access to a standard Python environment, where you can also install third-party libraries. This can for example be used to install a ML library and then execute a trained model within this module.
Custom modules
For full freedom you also have the option to build your own modules and add them to your library. Using our .NET SDK only your imagination sets the limits!
FlowWatch - Monitor your Flows and your data
Having use cases running in distributed environments can be a challenge, if you don't know what is happening. This is where Crosser FlowWatch comes in. Even though no processed data is sent to the Control Center, the Nodes and Flows will report status on a regular basis, as well as any anomalous events detected. This data forms the basis for the monitoring part of the Control Center.
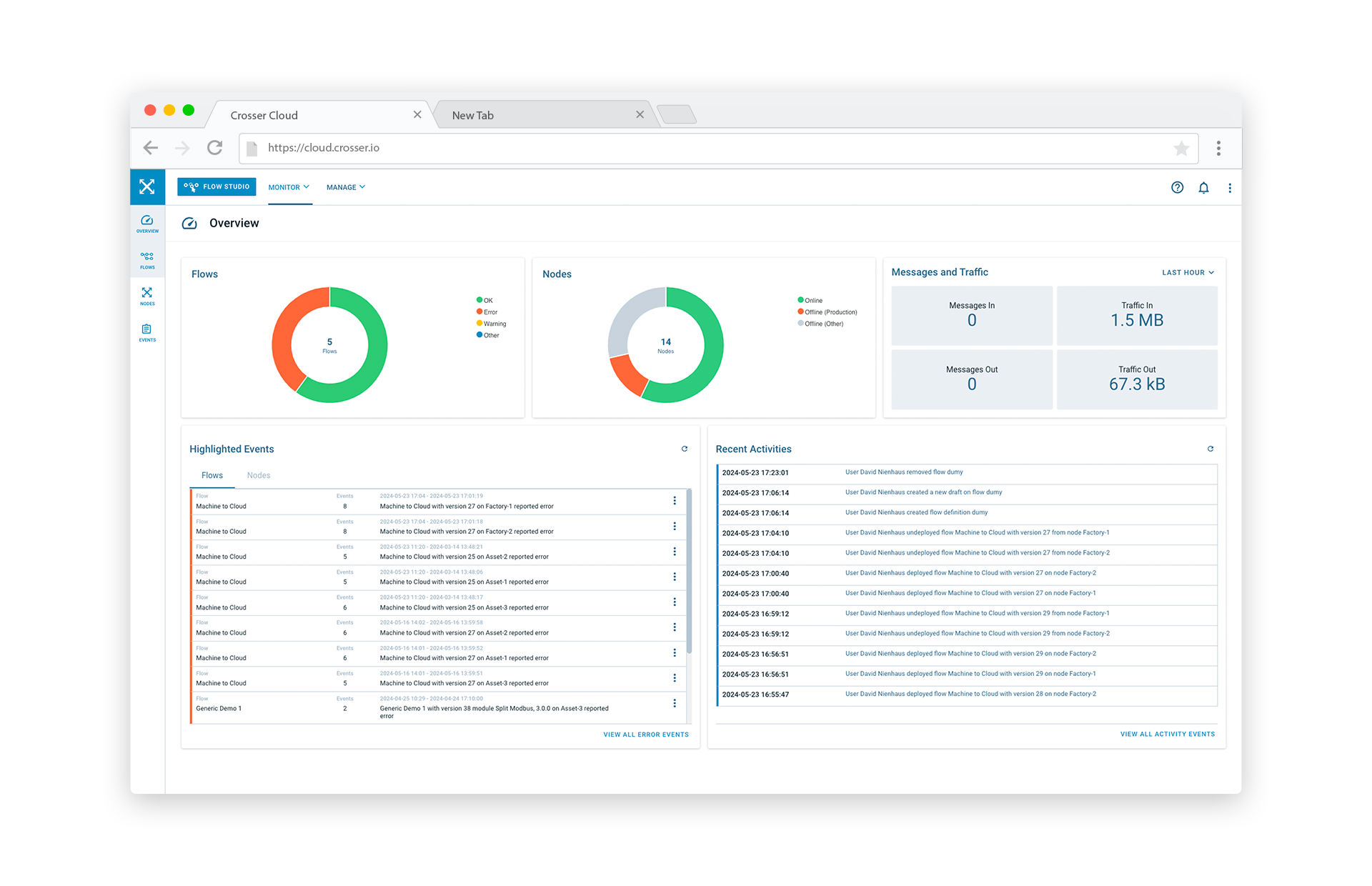
You can quickly get an overview of the status of your current setup, but also tools to steer your attention into issues that may need to be addressed. Drill-down until you find the root cause. Clearable error counters make sure you don't miss that single event that occurred two days ago.
Flow specific monitoring
The automatic monitoring will help you to take care of many issues. But sometimes you want to identify issues that are specific to a Flow, e.g. you want to check that data arrives as expected, or that the characteristics of your data meets your expectations and doesn't change over time. For these situations you can instrument your Flows with additional modules just for monitoring purposes. Send notifications to the relevant staff when you detect issues.
Nodes
The Crosser Node is the execution environment for Flows. A single Node can run multiple Flows and Flows run independent of each other, i.e. you can update an existing Flow or add a new Flow without affecting other Flows running on the same Node. Once deployed a Flow will run until stopped or removed. Nodes can be installed either as a Docker container or as a Windows service and you can have any number of Nodes in your setup. Each Flow can be deployed into one or several Nodes.

Search Documentation
Page Sections