The use of machine learning (ML) models is becoming more and more common in industrial IoT applications, especially for use cases such as anomaly detection and predictive maintenance. ML models are typically trained in the cloud using large stored datasets and iterative processing on powerful servers. When it comes to executing the model on new live data, called inference, the cloud may not be the most optimal place. For many use cases the most natural place for executing ML models is at the edge, close to the data source. There are several reasons for this:
- Latency - Machine-to-machine or other on-premise use cases may have latency requirements that cannot be met with inference in the cloud.
- Data volume - If many sensors need to be analyzed by the ML model the shear data volume may make cloud inference impractical and/or too costly.
Deploying and maintaining ML models at the edge may be challenging, especially if many edge sites are in operation. This is where Edge MLOps comes into play. How to manage your ML models at the edge? The Crosser Edge Streaming Analytics solution provides several tools to simplify your Edge MLOps.
Collect and adapt data, deliver results
When executing ML models at the edge with live data it’s not only the ML model you need to consider.
- First of all you need to get hold of the data, from machines or other data sources, possibly using different protocols and data formats.
- Then, you need to prepare the data. In a live environment you get streaming data from each sensor independently, while the ML models expects samples with data from each sensor in a specific order. To solve this you need some way to time-align the live streams and possibly re-order the data. You may also have sensors that delivers data with different frequencies, so that data from slower sensors must be repeated or interpolated to fill up the samples expected by the ML model.
- Finally, you need to deliver the results of the ML inference, whether it’s a trigger that should be sent to some onsite machine or system, or some insights that should be delivered to an IT system, locally or in the cloud.
The Crosser solution has pre-built modules to handle all of these steps:

Manage models and code
Executing ML models typically requires the following:
- An ML model file, exported from the toolchain used to train the model
- An execution environment. In most cases this is the same framework used for training, or a subset thereof, like Tensorflow, Scikit-learn or Pytorch. Model exchange formats like ONNX will open up for generic execution environments.
- Code to initiate the ML framework and load the model file.
The Crosser solution provides a centralized Resource Library where you upload your ML models and code snippets. These are then automatically distributed to the edge nodes that need them. Updating any number of edge nodes with new ML models or code is then a single operation that is easily initiated from the Crosser Cloud service. Through version control it is easy to compare different generations of the model, keep track of when updates have been introduced and to roll-back to a previous version if issues were found.

Resources (ML models, Python Scripts ⇒ Flow (Versions) ⇒ Edge Nodes (Groups)
Test your models with real data
Executing an ML model in a live streaming environment may not be identical to the environment used for training. Therefore it is important that you can test and evaluate the ML models in the edge environment. The Crosser solution supports interactive debugging tools that make it possible to evaluate the model with real data available to the distributed edge node. Both graphical timeline views of any parameter and detailed message inspection are available to verify the model before actual deployment.
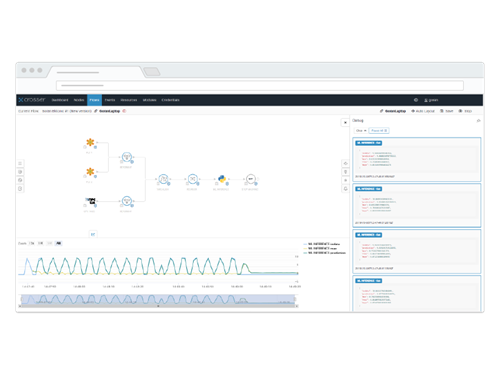
In summary, the Crosser Edge Streaming Analytics solution is a pre-packaged solution for industrial IoT applications that simplifies the deployment and life-cycle management of all your ML models running at the edge, i.e. the perfect companion for your Edge MLOps!
Key requirements that the Crosser Platform addresses include:
- Visualize and store all models available for deployment
- Ways to include the ML models in a context without having to write all code for collecting, preparing and acting on data
- A runtime environment in the edge that is easily managed
- Orchestration and mass deployment of ML models and processing flows
- Version control making updates simple, secure and managed