Best Practice File Upload
We see many use cases where a large volume of data is to be stored in cloud storages with focus on cost efficiency rather than latency. In these cases it is usually more efficient to upload files directly into a Blob Storage rather than streaming it to a cloud service and creating files from that stream which are then stored in the Blob. To come up with the most stable approach we recommend to separate data acquisition from data upload.
The example below shows a setup where we create parquet files with data from on-prem systems, store those files on the local filesystem and upload them with a different flow to Azure. Once the files are uploaded they are deleted from the local filesystem.
Flow 1: Data to parquet file
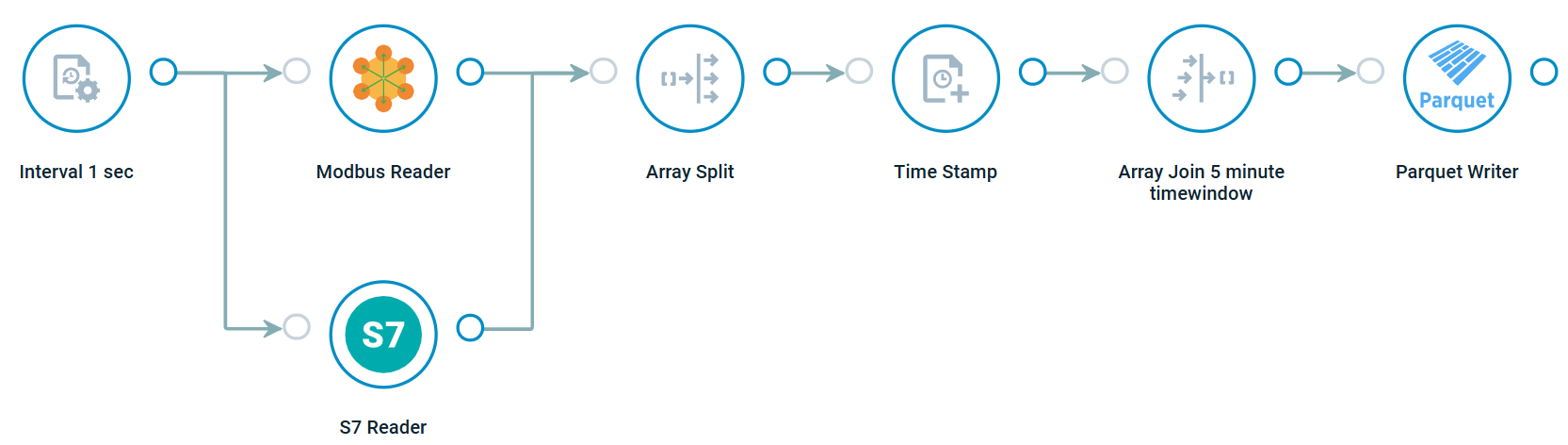
Crosser Example Flow
Flow 2: File upload

Crosser Example Flow
With this concept you can upload multiple files in one go and also make sure that no files will be left. Even if the upload fails, the process will try to upload the files in the next iteration.
